

🌳 Binary Trees in Frontend Development
I was stuck on Binary Trees until I learned this. | ♻️ Knowledge seeks community 🫶 #7

Hi there,
Hope you’re having a nice week!
Recently, I had a technical task for one of the companies I applied to, and one of the problems involved Binary Trees. At first, I didn’t understand how this problem related to my frontend skills or why I was being tested on it. I must admit that I had encountered this topic a couple of times in algorithmic challenges on platforms like LeetCode and HackerRank, but my understanding of it was not very strong.
After completing the technical test, I took some time to research and gain a better understanding of how Binary Trees work and how they relate to Frontend Development.
Let’s dive in … ⬇️
What is a Binary Tree Data Structure?
A Binary Tree Data Structure is a hierarchical data structure in which each node has at most two children, referred to as the left child and the right child. It is commonly used in computer science for efficient storage and retrieval of data, with various operations such as insertion, deletion, and traversal.
Source: https://www.geeksforgeeks.org/binary-tree-data-structure/
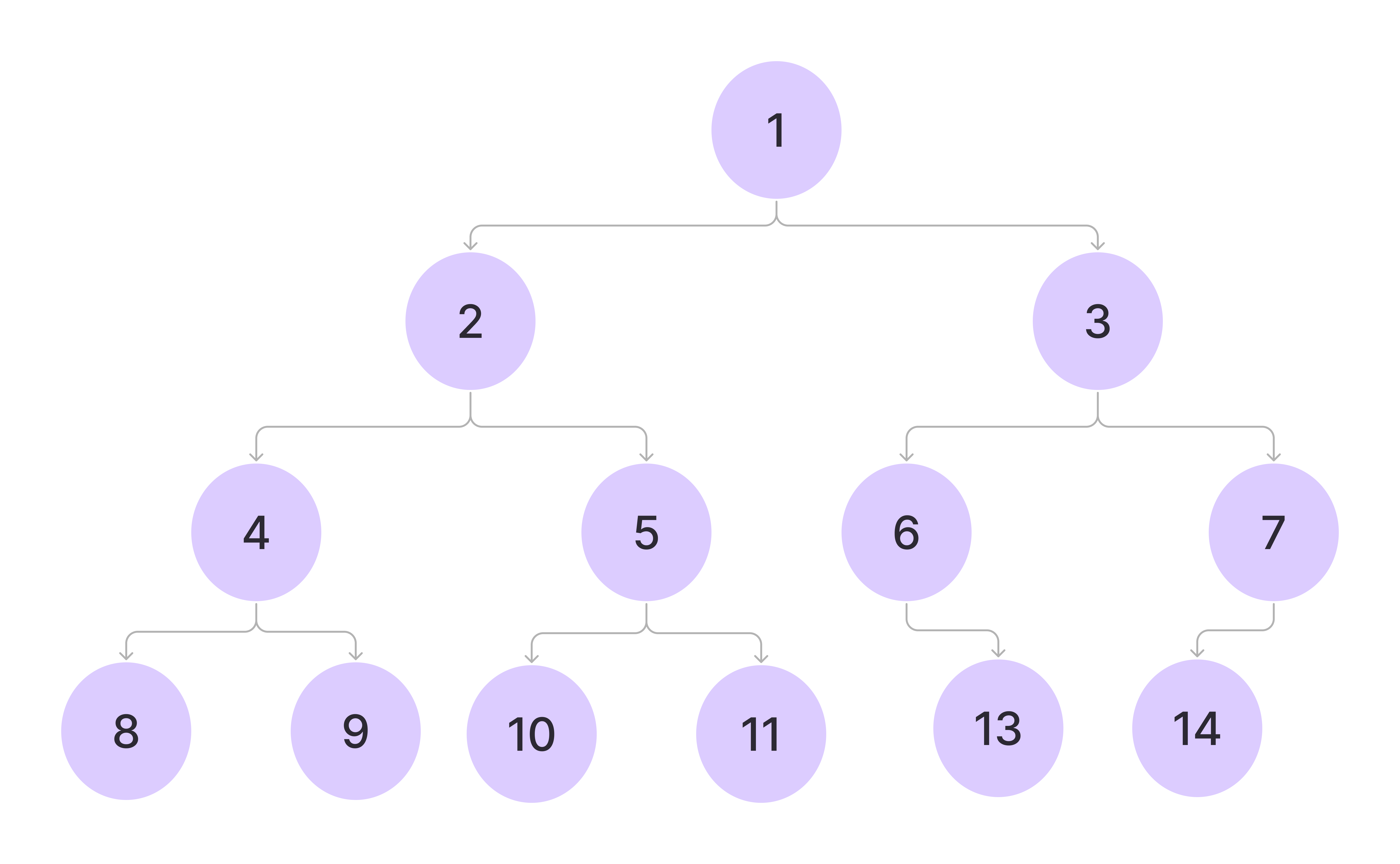
Ok.. So how is it related to Frontend Development?
While binary trees aren't commonly used directly in everyday frontend development, their underlying principles and structures influence many key aspects of latest frontend work - from Virtual DOM in React, Routing in Frontend Frameworks, Component Hierarchy, Efficient Lookups and State Management, to the Accessibility Tree of a browser and CSS Engines.

Let’s explore two areas in which binary trees are being used at the base:
➡️ Virtual DOM Tree and Efficient Re-Renders
We have a React component tree like this:
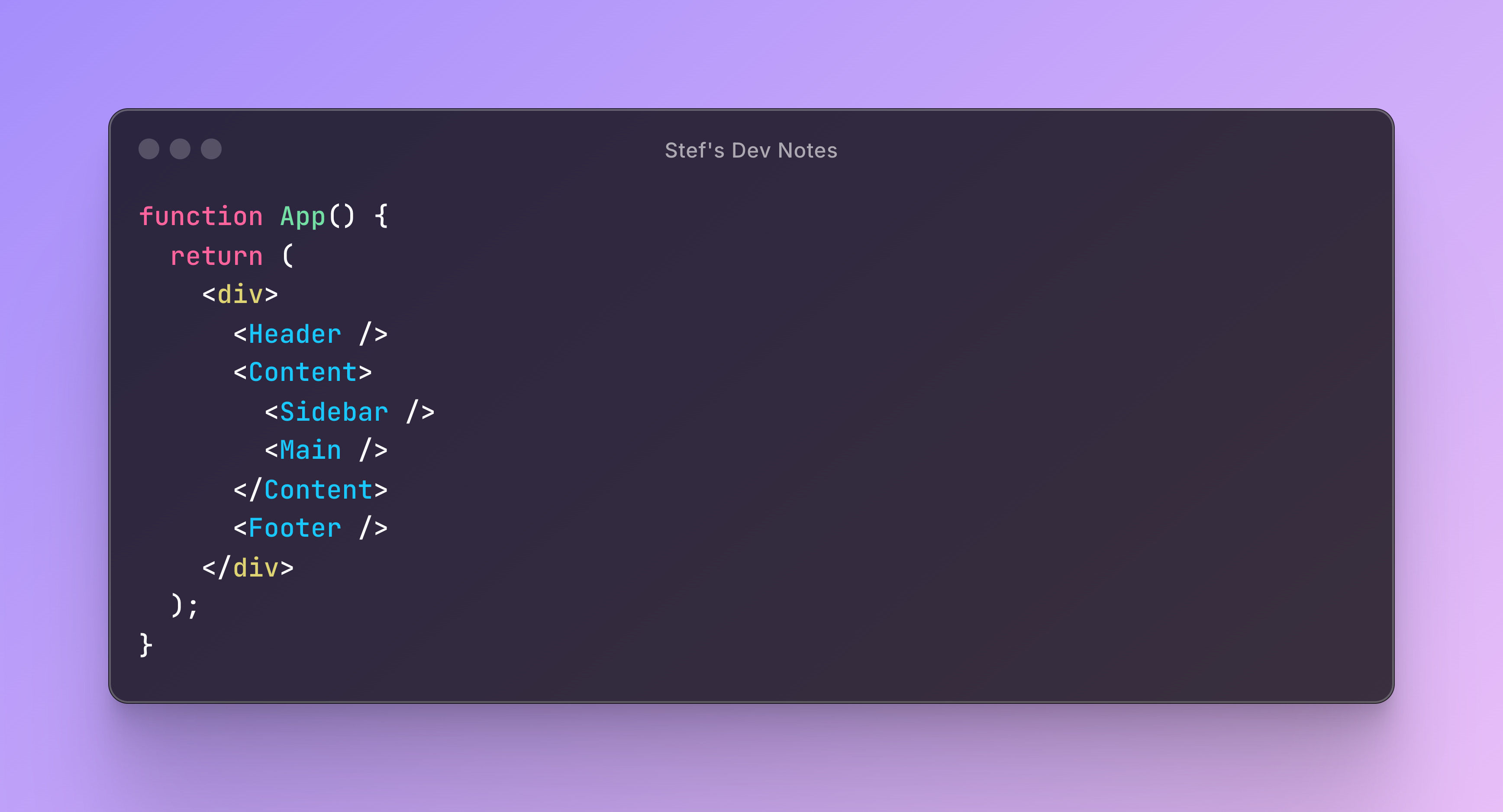
This creates the following tree structure:
App
├── Header
├── Content
│ ├── Sidebar
│ └── Main
└── FooterWhat Happens When State Changes?
Let’s say a state update happens in the
<Main />component.React builds a new tree representing the updated state.
React then diffs the old tree with the new tree using a tree-based algorithm:
It starts at the root (
App).It checks if the
Appnode has changed.If yes, it updates it.
If no, it moves to its children.
It continues recursively down the tree.
React applies the minimum number of updates to the real DOM based on the diffing result.
If the state changes only in <Main/> the diffing result will look like this:
Before State: After State:
App App
├── Header ├── Header
├── Content ├── Content
│ ├── Sidebar │ ├── Sidebar
│ └── Main (A) │ └── Main (B) <— Changed!
└── Footer └── FooterAnd this means that React will skip updating Header, Content, Sidebar and Footer because they haven’t changed and it will only update one node - Main.
Another case where binary tree principles come into play is when using useMemo and useCallback to prevent unnecessary re-renders of sibling components.
If you want to see how these two hooks are working under the hood and when to use them, you can read in one of my latest articles:

How Tree Diffing Works Internally
React uses the Fiber tree algorithm which is an optimized tree structure and does the following actions:
It assigns a unique key to each node.
If the keys match between the old and new tree, it keeps the existing node.
If the keys are different, it destroys the old node and creates a new one.
For example, if you add a new Sidebar with the same key, React will keep the existing tree structure and only patch in the changes.
Why Trees Matter Here
Tree diffing allows React to avoid expensive full tree re-renders.
Understanding the tree traversal process helps you write more efficient components.
Using keys,
React.memo,useMemo, anduseCallbackstrategically helps React short-circuit tree traversal and improve rendering performance.
Takeaway:
Understanding the underlying tree structure helps you:
Write more performant React components.
Avoid unnecessary re-renders.
Optimize complex UI updates with minimal DOM operations.
➡️ CSS Engines
CSS engines (like those in Chrome’s Blink or Firefox’s Gecko) often rely on tree structures — including binary trees — under the hood for efficient parsing, rendering, and matching.
CSS Selector Matching:
When a browser processes your CSS, it has to match the selectors against the DOM elements. This is not a trivial task because:
CSS allows complex selectors like
.container > .item:first-child + .activeThe browser has to efficiently handle conflicts and specificity
How It Works:
The CSS engine builds a Selector Tree to store and manage the selectors.
When an element is rendered, the engine searches the tree to find the correct matching rule.
The tree-based structure allows efficient matching.
Let’s take the following example:
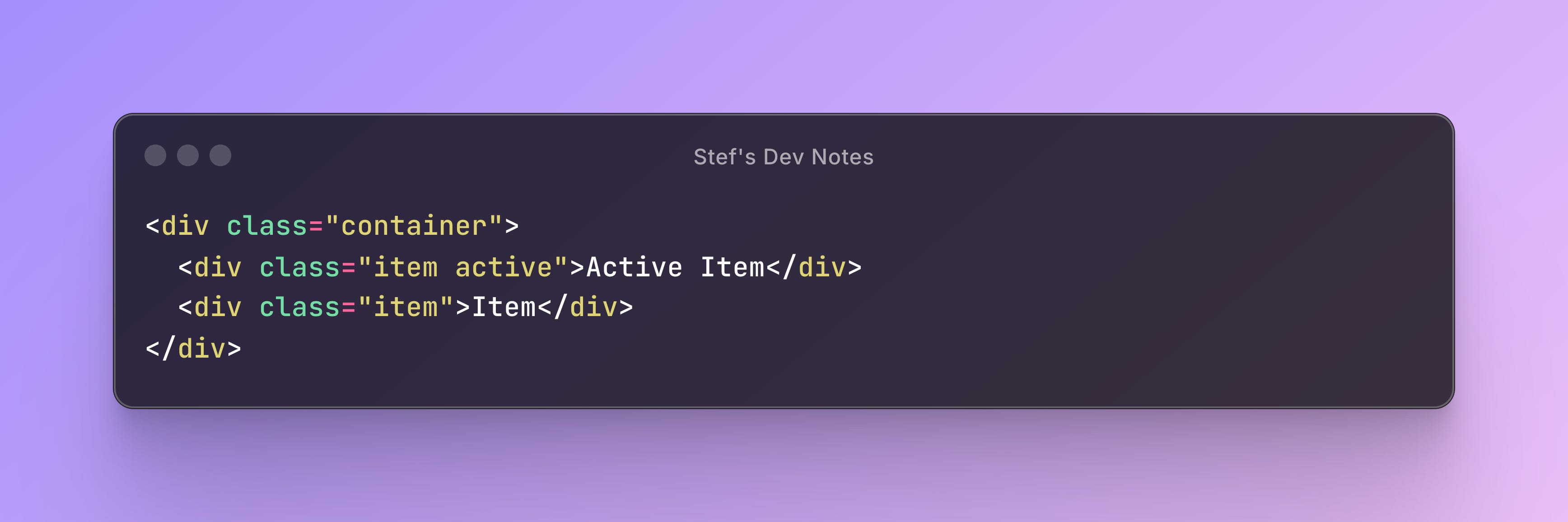
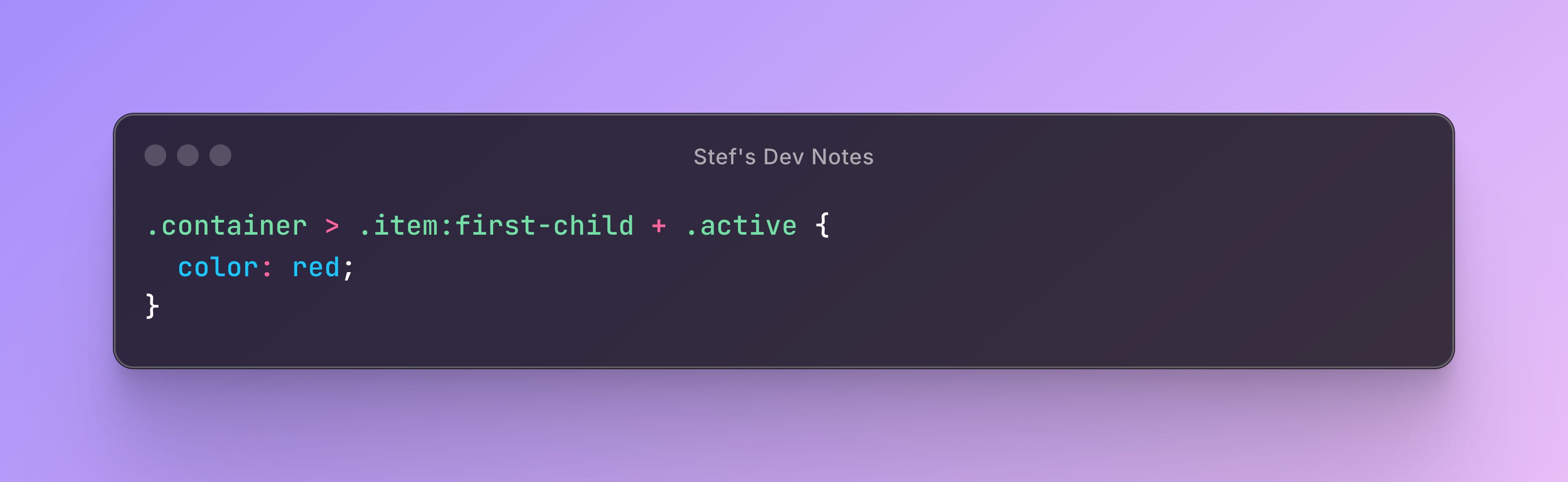
The browser will use the following tree in order to break down the given selector:
>
/ \
.container +
\
.item:first-child
\
.activeAnd the search to match the selector with the DOM element will follow like this:
Start at the root node (
>).Move left or right based on the selector hierarchy.
Check for a match.
This tree allows the engine to avoid searching the entire DOM — instead, it navigates down the tree structure, reducing the search time from O(n) to approximately O(log n).
Style inheritance and computation:
CSS inheritance is hierarchical by nature — similar to a tree:
div→p→spancreates a parent-child relationship.The browser computes styles using a tree-based traversal (like a depth-first search).
Example:
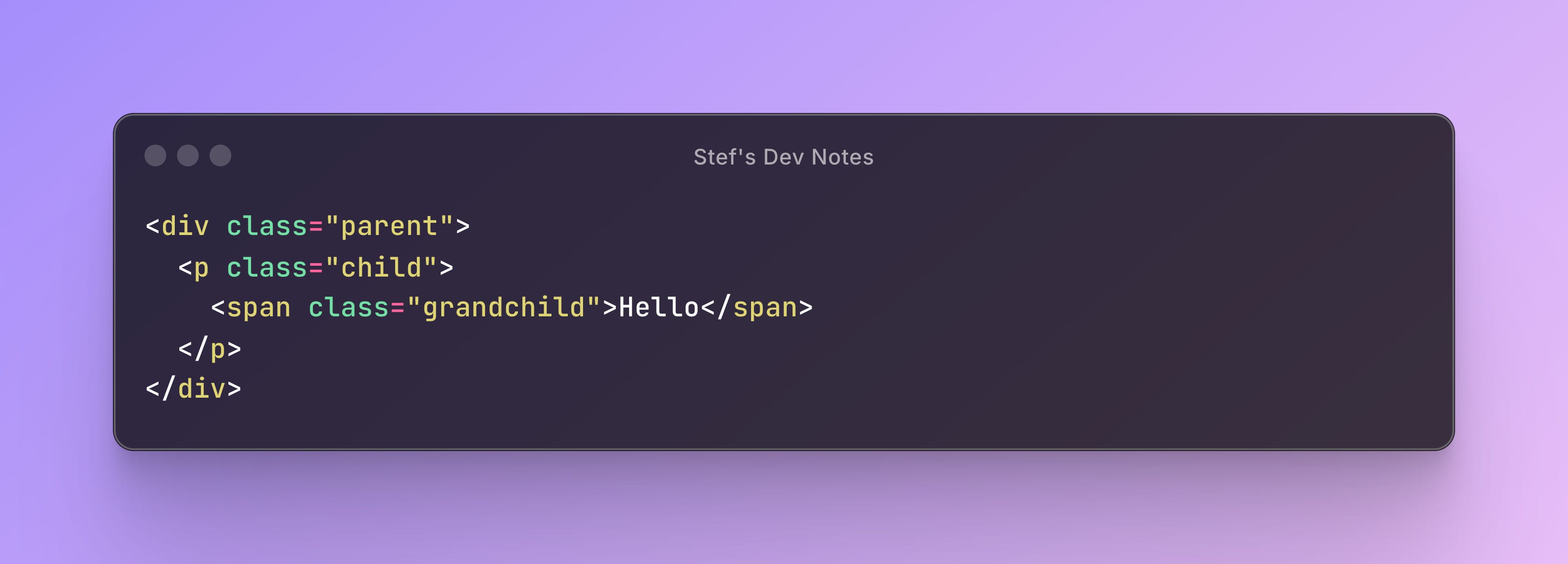
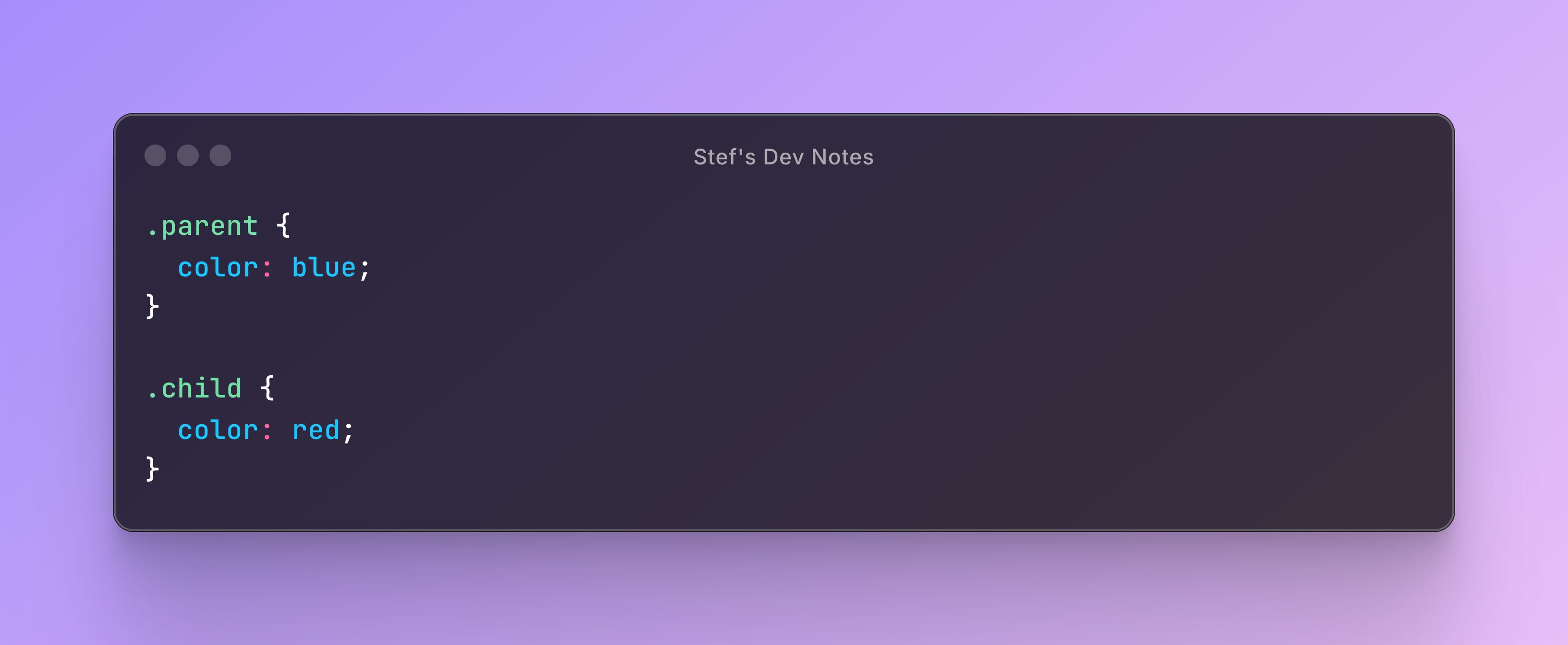
How It Works:
The DOM and CSSOM trees are merged into a Render Tree:
parent └── child └── grandchildThe browser calculates styles using a tree traversal:
Start at the root (parent).
Apply styles.
Override as it moves down the tree (if needed).
Here, the Binary tree search helps avoid redundant calculations and ensures that inherited styles are efficiently computed.
Takeaway:
CSS engines use tree-based structures (sometimes binary) to:
Optimize selector matching
Resolve conflicts based on specificity
Compute inherited styles efficiently
These are just two examples of how binary tree principles are applied in frontend development, highlighting why understanding them can be valuable for frontend engineers.
While I’m still working on improving my grasp of these algorithmic concepts, it's great to discover how they influence frontend development — even if they don’t directly come up in my day-to-day work (and probably not in yours either).
Until next time 👋,
Stefania
P.S. Don’t forget to like, comment, and share with others if you found this helpful!
Other articles from the ♻️ Knowledge seeks community 🫶 collection: https://stefsdevnotes.substack.com/t/knowledgeseekscommunity
👋 Get in touch
Feel free to reach out to me here on Substack or on LinkedIn.
This is insightful. It's nice to see how data structures are used in real projects outside the academic realm and notebooks.